
基本概念
时间复杂度是衡量算法效率的核心指标,描述算法运行时间与输入规模的关系。它不关注具体运行时间(如毫秒数),而是关注随着输入规模 n 增大时,算法运行时间的增长趋势。
为什么关心时间复杂度?
- 评估效率:比较不同算法在解决同一个问题时的效率,则优选择。
- 预测性能:预测算法在处理大规模数据时的表现。
- 优化算法:识别算法中的性能瓶颈,指导优化方向。
- 跨平台比较:不同硬件上的实际运行时间会有差异,而时间复杂度是平台无关的
在实际应用中,一个时间复杂度更优的算法,即使在小规模数据下可能与效率较低的算法差异不大,但在处理大规模数据时,其优势会非常显著。
大 O 记法
我们通常使用大 O 记法(Big O Notation)来表示算法的渐进时间复杂度。渐进时间复杂度描述的是当输入规模 n 趋近于无穷大时,算法执行时间增长的上界。
大 O 记法忽略了常数项和低阶项,只保留对增长速度影响最大的项。例如,如果一个算法的基本操作执行次数是
大 O 记法的规则:
- 忽略常数项: O(c) 表示 O(1),其中 c 是常数。
- 忽略系数: O(c⋅f(n)) 表示 O(f(n)),其中 c 是常数。
- 忽略低阶项: O(
) 表示 O( )。
时间复杂度计算方式
- $2n^2+3n+4$$ n^2 $
示例:
def sum_array(arr):
total = 0 # 执行1次
for x in arr: # 循环执行 n 次
total += x # 执行 n 次 (基本操作)
return total # 执行1次在这个例子中,基本操作是 total += x。循环执行了 n 次(假设数组 arr 的长度为 n)。其他操作(变量初始化、返回)的执行次数是常数。
总执行次数 T(n)=1+n+n+1=2n+2。
根据大 O 记法规则:
- 忽略常数项:2n
- 忽略系数:n
所以,时间复杂度为 O(n)。
时间复杂度增长速度对比:
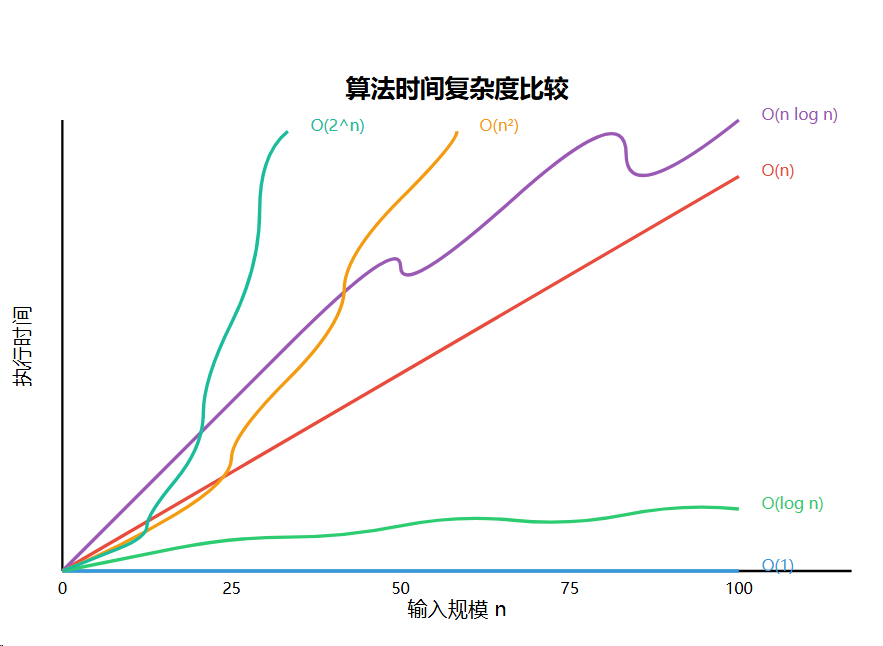
O(1) < O(
在实际应用中,我们通常追求多项式时间复杂度(O(
示例
O(1)-常数时间复杂度
无论输入规模多大,算法执行时间都是固定的。
例子: 访问数组中的一个元素(通过索引)、简单的算术运算。
def get_first_element(arr):
return arr[0] # 执行1次O(
算法执行时间随输入规模呈对数增长。通常出现在分治算法中,如二分查找。每次操作都将问题规模减半。
例子:二分查找
def binary_search(array, target):
left = 0
right = len(array) - 1
while left <= right:
mid = (left + right) // 2
if array[mid] == target:
return mid
elif array[mid] < target:
left = mid + 1
else:
right = mid - 1
return -1O(n) - 线性时间复杂度
算法执行时间与输入规模成正比。
例子: 遍历数组、查找链表中的元素。
def find_element(arr, target):
for x in arr: # 最坏情况下执行 n 次
if x == target:
return True
return FalseO(
通常出现在高效的排序算法中,如归并排序、快速排序(平均情况)。
例子: 归并排序。
def merge_sort(array):
if len(array) <= 1:
return array
mid = len(array) // 2
left = merge_sort(array[:mid])
right = merge_sort(array[mid:])
return merge(left, right)
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] < right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return resultO(
算法执行时间与输入规模的平方成正比。通常出现在嵌套循环中。
例子: 冒泡排序、选择排序、简单的矩阵乘法。
def bubble_sort(arr):
n = len(arr)
for i in range(n): # 外层循环 n 次
for j in range(0, n - i - 1): # 内层循环最多 n 次
if arr[j] > arr[j + 1]: # 基本操作
arr[j], arr[j + 1] = arr[j + 1], arr[j]O(
算法执行时间随输入规模呈指数增长。这种算法效率非常低,只能处理很小规模的问题。
例子: 求解旅行商问题(朴素方法)、递归计算斐波那契数列(无备忘录)。
def fibonacci(n):
if n <= 1:
return n
return fibonacci(n - 1) + fibonacci(n - 2)O(
算法执行时间随输入规模呈阶乘增长。效率极低,几乎只能处理微小规模的问题。
例子: 生成所有可能的排列组合(朴素方法)。
递归算法时间复杂度分析
递归算法比较难分析,有些常用的方法可以帮助我们快速分析递归算法的时间复杂度。
基本步骤可以简化为两步:
- 写出递归关系:
- 确定基本情况的时间复杂度。当递归停止时,通常是常数时间 O(1)。
- 确定递归步骤的时间复杂度。这包括:
- 每次递归调用本身的开销。
- 递归调用之外的其他操作(如分割问题、合并结果)的开销。
- 将这些开销结合起来,写出 T(n) 的递归关系,其中 T(n) 表示输入规模为 n 时的总时间。
- 求解递归关系:
有几种常用的方法来求解递归关系:
- 代入法 (Substitution Method) :猜测解的形式,然后用数学归纳法证明。
- 递归树法 (Recursion Tree Method) :画出递归调用的树状结构,计算每层的开销,然后求和得到总开销。
- 主定理 (Master Theorem) :对于特定形式的递归关系,可以直接套用公式得出解。
主定理
主定理方法直接提供了一套公式的计算法,直接套用公式即可,这里不做公式证明,只直接套用使用。
$T(n)=aT(\frac{n}{b})+f(n)$- __
注意:主定理不是万能的,它只适用于特定形式的递归关系
主定理通过比较非递归部分的开销 f(n) 与一个关键项
f(n) 的增长速度慢于
如果存在常数 ϵ>0,使得
直观理解: 在这种情况下,递归树的叶子节点的总开销占主导地位。
例子:T(n)=4T(n/2)+n
- 这里 a=4, b=2, f(n)=n.
- 计算
- 比较 f(n)=n 和
- n 的增长速度比 n2 慢。
- 根据情况 1,
f(n) 的增长速度等于
如果存在常数 k≥0,使得
最常见的情况是 f(n)=O(n^{log_b{^a}})$即 k=0。在这种情况下,如果
如果
直观理解: 在这种情况下,递归树的每一层(或大致每一层)的开销都与
例子:T(n)=2T(n/2)+n (归并排序的递归关系)
- 这里 a=2, b=2, f(n)=n.
- 计算
- 比较 f(n)=n 和
(即 k=0) - 根据情况 2,
f(n) 的增长速度快于
如果存在常数 ϵ>0,使得
则:
直观理解: 在这种情况下,非递归部分的开销 f(n) 占主导地位。正则条件确保了非递归开销在递归过程中不会增长得过快,使得顶层(或靠近顶层)的开销是最大的。
例子:T(n)=2T(n/2)+
- 这里 a=2, b=2, f(n)=
. - 计算
- 比较 f(n)=
和 的增长速度比 n 快。
检查正则条件:af(n/b)≤cf(n)
1/2 <=c
我们可以选择 c=1/2,它小于 1。正则条件满足。 根据情况 3, T(n)=Θ(f(n))=Θ($n^2$).
示例
def binary_search(arr, target, low, high):
if low > high: # 基本情况 1
return -1 # O(1)
mid = (low + high) // 2
if arr[mid] == target: # 基本情况 2
return mid # O(1)
elif arr[mid] < target: # 递归步骤 1
return binary_search(arr, target, mid + 1, high) # 递归调用
else: # 递归步骤 2
return binary_search(arr, target, low, mid - 1) # 递归调用直接使用公式分析:
- 子问题数量 a:在每次递归中,我们只选择一个子区间(左半部分或右半部分)继续搜索,所以 a = 1。
- 子问题规模缩减因子 b:每次递归调用将搜索范围减半,所以 b = 2。
- f(n):在每一层递归中,我们执行的操作:
- 计算中间索引 mid
- 比较 arr[mid] 和 target
- 决定搜索左半部分还是右半部分
这些操作都是 O(1) 的,所以 f(n) = O(1)。
- 比较 f(n) 和
- f(n)=n^{log_b{^a}}$ (更准确地说,f(n) 与
属于同一量级)。根据主定理的第二种情况( ),时间复杂度为 。
再看一个示例
def merge_sort(array):
if len(array) <= 1:
return array
mid = len(array) // 2
left = merge_sort(array[:mid])
right = merge_sort(array[mid:])
return merge(left, right)直接使用公式分析:
- 子问题数量 a:进行了两次递归,所以 a = 2。
- 子问题规模缩减因子 b:每次递归调用将搜索范围减半,所以 b = 2。
- f(n):在每一层递归中,我们执行的操作:
- 计算中间索引 mid 常数级别
- 比较 arrary长度 常数级别
- 合并操作O(n)
这些操作最大是O(n),所以 f(n) = O(n)。
- 比较 f(n) 和
- $n^{log_b{^a}}=n^{log_2{^2}}=n^1=n $ $ f(n) = O(n)$
根据主定理的第二种情况( ),时间复杂度为 。
代入法
代入法也是求解递归关系的一种重要方法,尤其适用于主定理不直接适用的情况 。它的核心思想是猜测递归关系的解的形式,然后使用数学归纳法来证明这个猜测是正确的。
通用的分析框架
无论递归算法多复杂,使用代入法分析时间复杂度都可以遵循以下通用步骤:
- 识别基本操作:确定算法中的基本操作,这些操作通常决定了算法的复杂度。
- 建立递推关系:根据递归调用的方式,建立时间复杂度的递推关系式。常见的形式有:
- T(n) = T(n-1) + f(n) (减小常数)
- T(n) = T(n/2) + f(n) (减半)
- T(n) = 2·T(n/2) + f(n) (分治)
- T(n) = T(n-1) + T(n-2) + f(n) (多路递归)
- 根据经验猜测:根据递推关系的形式和f(n)的增长率,猜测T(n)的增长率。一些常见的对应关系:
- T(n) = T(n-1) + O(1) → O(n)
- T(n) = T(n/2) + O(1) → O(
) - T(n) = 2·T(n/2) + O(n) → O(
) - T(n) = T(n-1) + T(n-2) + O(1) → O(
)
- 代入验证:将猜测的解代入递推关系式,验证是否成立。
- 必要时调整:如果验证失败,调整猜测并重新验证。
示例
def sum_num(n):
if n == 1:
return 1
else:
return n + sum_num(n-1)步骤1:建立递推关系式
T(n) = T(n-1) + c
步骤2:猜测解
我们猜测时间复杂度为O(n):
T(n) = O(n)
步骤3:验证猜测
假设T(n) ≤ d·n(d为某个正常数)
代入递推关系式: T(n) = T(n-1) + c ≤ d·(n-1) + c = d·n - d + c
只要d ≥ c,就有: d·n - d + c ≤ d·n
这验证了我们的猜测T(n) = O(n)是正确的。
递归树法
在代入法中,猜测解的形式是一个难点,而递归树法可以帮助解决这个问题。
递归树法是一种用来可视化递归算法执行过程并计算其总开销的方法。它通过绘制一棵树来表示递归调用,树中的每个节点代表一个子问题的开销。
使用递归树分析时间复杂度的步骤
- 画出递归树:根据算法的递归关系,画出完整的递归树
- 标记每个节点的工作量:在每个节点标明除递归调用外的基本操作数量
- 计算每一层的总工作量:将同一层所有节点的工作量加起来
- 计算总层数:确定递归树有多少层
- 计算总工作量:所有层的工作量加起来,就是算法的总时间复杂度()
绘制递归树就是要确定三个关键的要素:根节点、叶子节点、树的深度(层数)
根节点的确定
根节点代表原始问题,也就是我们最初调用递归函数时传入的参数。确定根节点非常直观:
- 原始问题参数:根节点就是表示原始递归调用的节点。例如,如果我们调用
mergeSort(arr, 0, n-1),那么根节点就是T(n),表示对大小为 n 的问题进行处理。 - 初始状态:根节点表示递归开始前的初始状态。比如在斐波那契数列计算中,如果我们要计算 F(5),那么根节点就是 F(5)。
- 从上到下的起点:递归树总是从根节点开始向下展开,表示问题分解的过程。
简单来说,根节点总是代表你正在解决的完整原始问题。
叶子节点的确定
叶子节点是递归树中没有子节点的节点,它们代表递归的基本情况(终止条件)。确定叶子节点的方法:
- 递归基本情况:叶子节点对应于递归函数中的基本情况。例如,在归并排序中,当数组长度为 1 时就不再递归,这时的
T(1)就是叶子节点。 - 不再进行递归调用:如果一个节点不再产生递归调用,那么它就是叶子节点。
- 问题规模达到最小:当问题被分解到不能再分的程度时,就到达了叶子节点。比如二分查找中,当搜索范围缩小到只有一个元素时。
- 递归函数中的返回语句:通常,递归函数中的直接返回语句(不再调用自身的返回语句)对应着叶子节点。
举例来说,在斐波那契递归计算中,F(1) 和 F(0) 是基本情况,它们在递归树中就是叶子节点。
层数的确定
递归树的层数表示递归的深度,它与问题分解的方式和终止条件密切相关:
- 问题规模的减小速度:层数与每次递归调用如何减小问题规模有关。
- 如果每次将问题规模减半(如二分查找、归并排序),层数通常是 log₂n
- 如果每次只减小常数大小(如斐波那契递归),层数通常是 n
- 确定层数的方法:
- 从根节点(层数为0或1)开始
- 计算从根节点到最深叶子节点的路径长度
- 这个路径长度加1就是层数(如果从0开始计数)
- 数学方法:解方程确定层数
- 设初始问题规模为 n
- 设每次递归使问题规模变为原来的 1/b
- 经过 k 层后,问题规模变为
- 当问题规模达到基本情况(通常是1)时:
= 1 - 解得:k =
例如,对于归并排序:
- 初始问题规模是 n
- 每次递归将问题规模减半,所以 b = 2
- 基本情况是当数组大小为 1 时
- 所以层数 k = log₂(n)
实际确定过程
在实际分析中,确定递归树的这些要素通常遵循以下步骤:
- 写出递归关系:如 T(n) = 2T(n/2) + n
- 确定递归终止条件:如 T(1) = c(常数)
- 画出递归树顶部几层:根据递归关系展开
- 计算问题规模如何变化:比如每次减半、减一等
- 计算达到终止条件需要多少层:如从 n 到 1 需要多少步
- 验证叶子节点是否符合终止条件:检查最底层节点是否为基本情况
示例
归并排序
归并排序的核心思想是:将数组分成两半,分别排序,然后合并结果。
def merge_sort(array):
if len(array) <= 1:
return array
mid = len(array) // 2
left = merge_sort(array[:mid])
right = merge_sort(array[mid:])
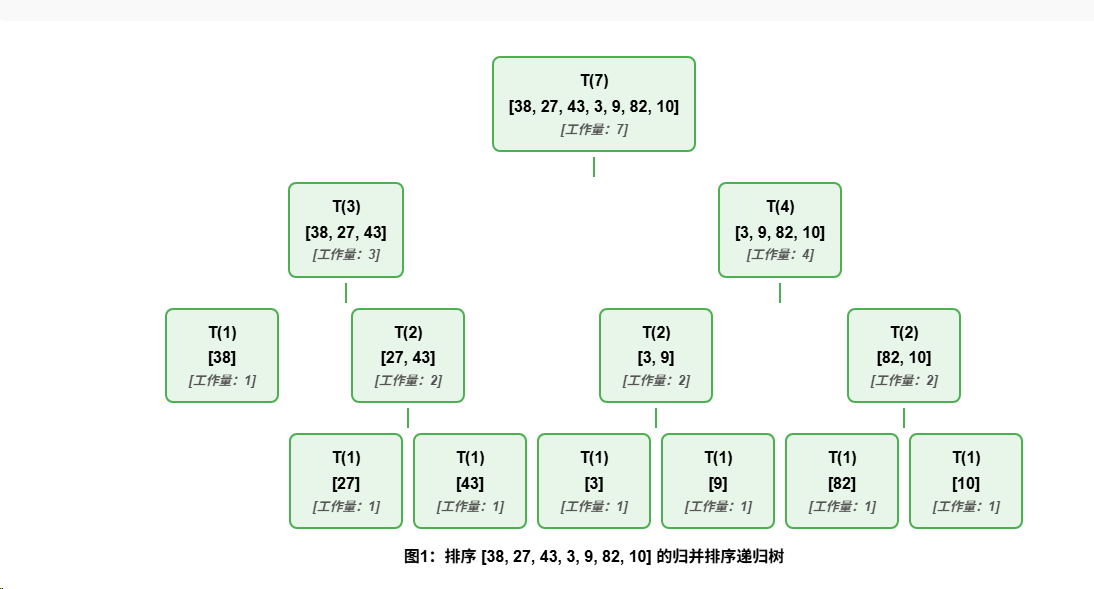
return merge(left, right)举个例子,我们对数组 [38, 27, 43, 3, 9, 82, 10] 进行排序。
根节点如何确定
根节点 T(7) 代表对整个7个元素的数组进行排序的任务。它是我们最初要解决的完整问题。
叶子节点如何确定
当数组长度为1时,我们到达了递归的"基本情况"。在这个例子中,叶子节点是:
T(1):[38]T(1):[27]T(1):[43]T(1):[3]T(1):[9]T(1):[82]T(1):[10]
这些节点不再需要进一步递归分解,因为单个元素的数组已经是排序好的。
层数如何确定
归并排序每次将问题规模减半,所以从规模n到规模1需要 log₂n 步。对于我们的例子:
- 初始规模是7
- log₂7 ≈ 2.8,向上取整是3
- 加上根节点层,总共有4层
时间复杂度分析
- 第1层:1个节点,工作量 = 7
- 第2层:2个节点,工作量 = 3 + 4 = 7
- 第3层:4个节点,工作量 = 1 + 2 + 2 + 2 = 7
- 第4层:7个节点,每个工作量为1,总工作量 = 7
每一层的总工作量都是n=7,总层数是log₂n≈3,所以总时间复杂度是O(n log n)。
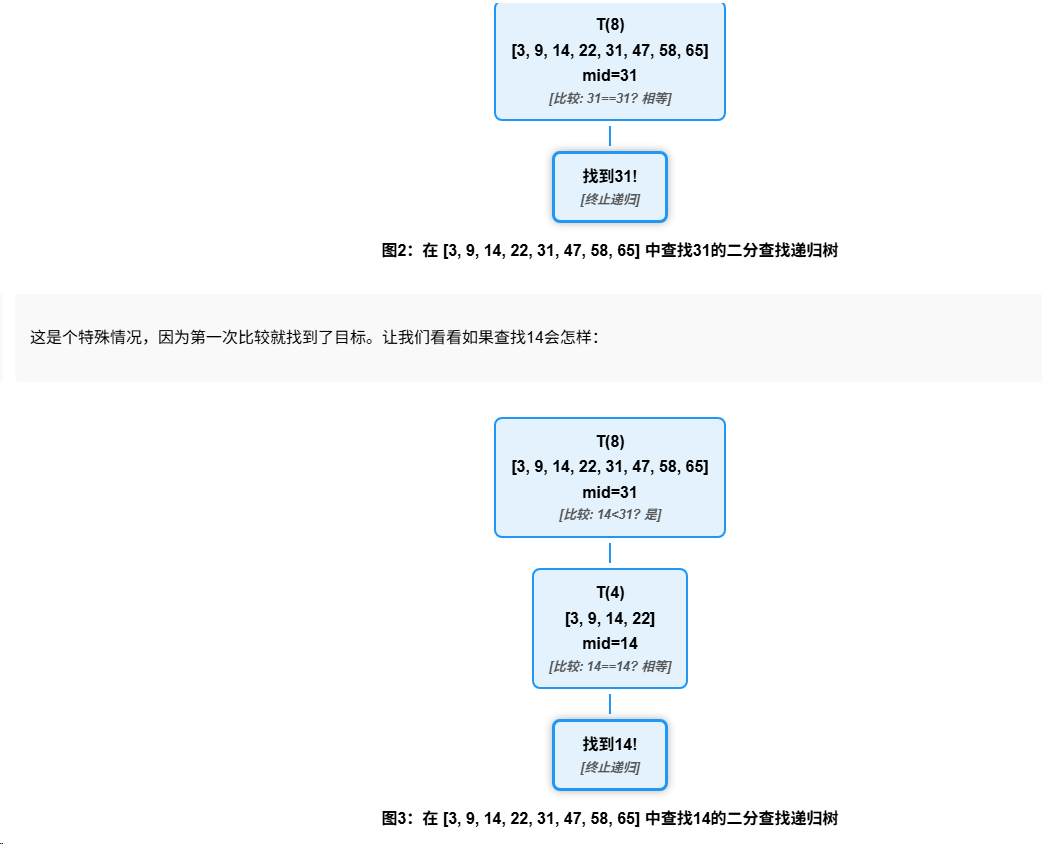
二分查找
我们在已排序数组 [3, 9, 14, 22, 31, 47, 58, 65] 中查找元素31和14。
根节点如何确定
根节点 T(8) 代表在整个8个元素的数组中查找目标值的任务。
叶子节点如何确定
叶子节点是我们找到目标值或确定它不存在的点。在第一个例子中,我们运气很好,第一次比较就找到了31。在第二个例子中,我们经过两次比较找到了14。
层数如何确定
二分查找每次将搜索范围减半,所以层数计算公式是log₂n。对于8个元素的数组:
- log₂8 = 3
- 加上根节点层,最多有4层
但在具体执行中,可能提前找到目标值而不需要探索完整的树。
时间复杂度分析
虽然在实际示例中我们提前找到了值,但二分查找的时间复杂度分析通常考虑最坏情况:需要log₂n次比较才能确定元素是否存在。所以时间复杂度是O(log n)。
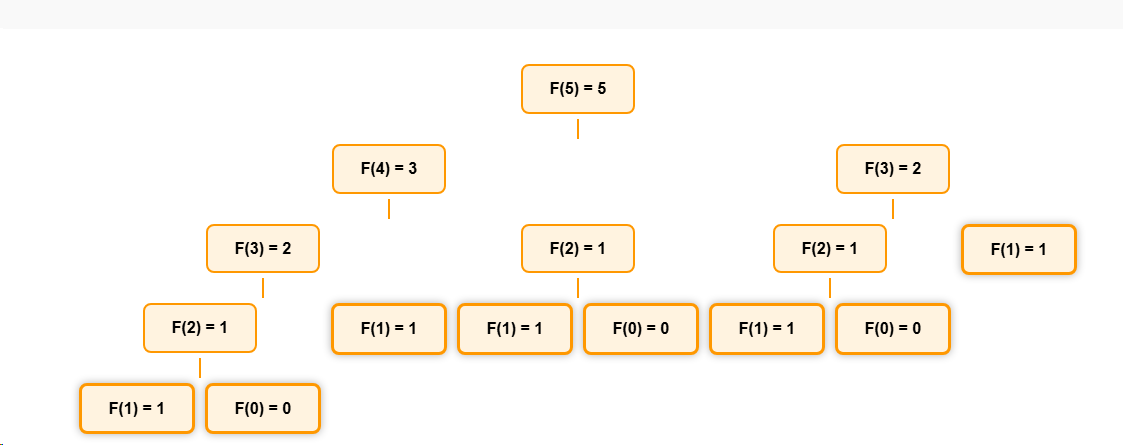
斐波那契
我们计算斐波那契数 F(5)。
根节点如何确定
根节点F(5)代表计算第5个斐波那契数的任务。
叶子节点如何确定
斐波那契递归的基本情况是F(0)=0和F(1)=1。所以所有的F(0)和F(1)节点都是叶子节点。在计算F(5)的过程中,我们会到达多
层数如何确定
从f(5)到f(1)或者f(0)一共用了5步,所以共有5层
时间复杂度分析
重复计算:
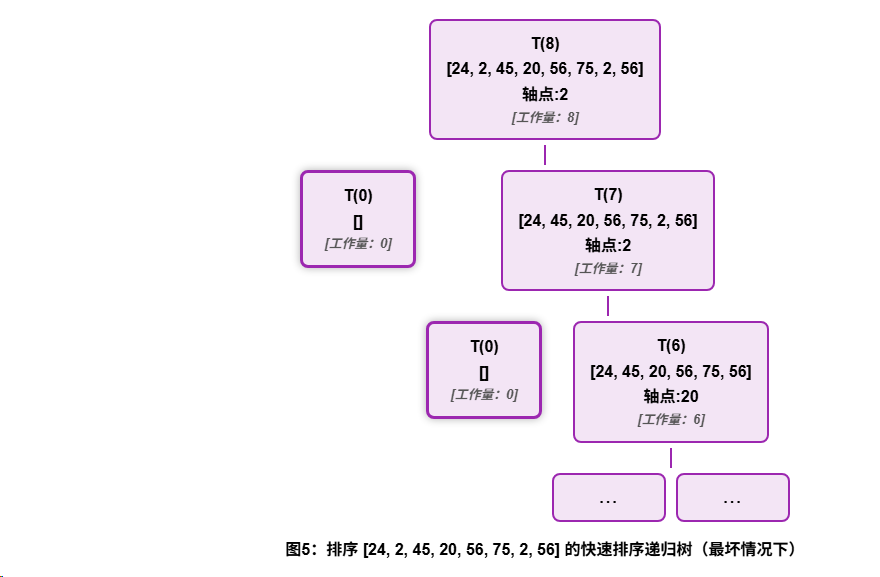
假设每次选择的轴点都是最小或最大元素 ,最坏的情况,
根节点如何确定
根节点 T(8) 代表对整个8个元素的数组进行排序的任务。它是我们最初要解决的完整问题。
叶子节点如何确定
,我们到达了递归的"基本情况"。层数如何确定
总工作量:
评论与讨论
如果这篇文章对你有帮助,或你对实现细节有不同判断,可以直接在这里继续讨论。