
 同一句 Prompt,今天让 AI 改 Bug,它像开挂;明天还是这句 Prompt,它像失忆。你以为是模型抽风,真相往往更朴素一点。
同一句 Prompt,今天让 AI 改 Bug,它像开挂;明天还是这句 Prompt,它像失忆。你以为是模型抽风,真相往往更朴素一点。
不是 Prompt 变差了,是你给它的上下文变脏了、变少了、变乱了,或者根本给错了。
上一章我们已经把 Prompt 工程掰开讲明白了。那一章解决的是“你怎么提需求”。这一章解决的是另一个更难的问题:你到底该把什么信息喂给模型,按什么顺序喂,喂多少才不把它喂撑,喂少了又不让它瞎猜。
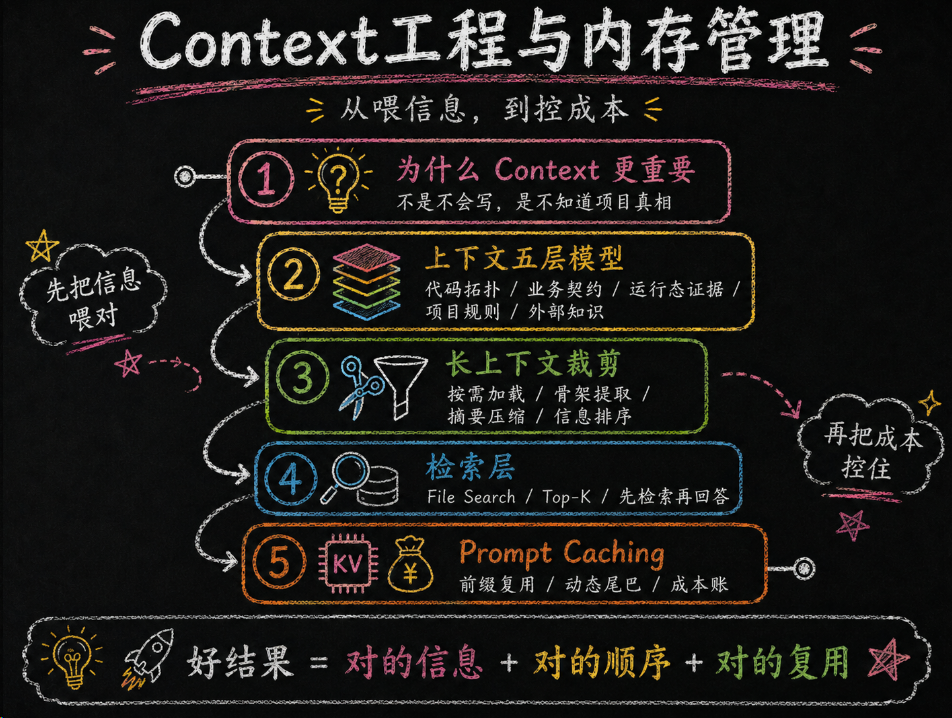
一、为什么 Context 工程经常比 Prompt 工程更重要
Prompt 像点菜单,上下文像后厨备料。菜单写得再漂亮,后厨没有菜,厨师也做不出你想吃的东西。
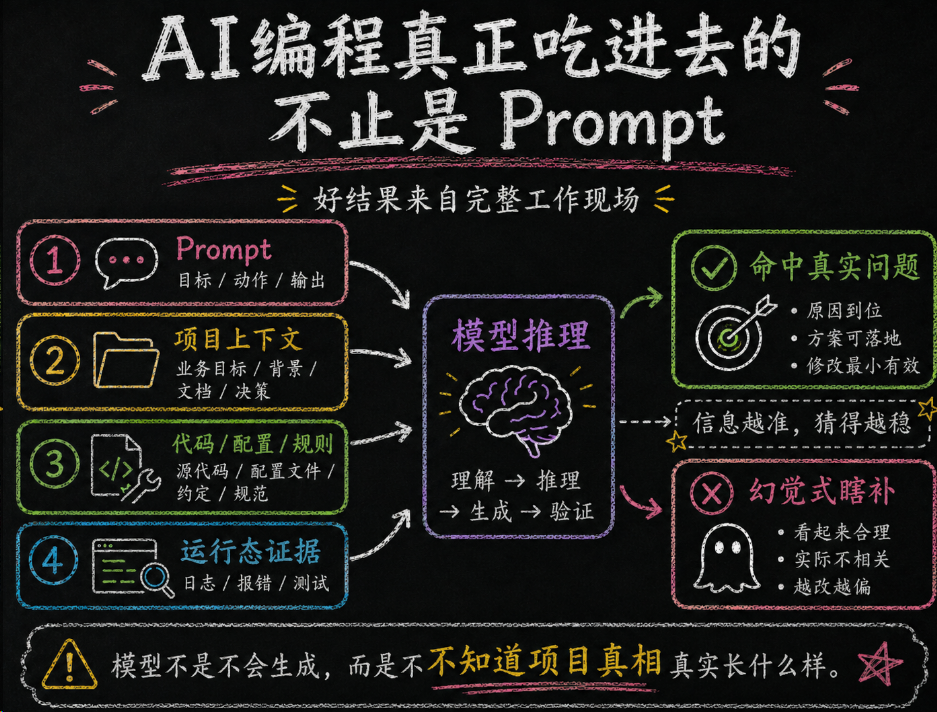
很多人把 AI 编程失败归因到“我 Prompt 写得不够好”。这话只对一半。另一半更关键:模型不是不知道怎么生成,而是不知道你这个项目现在真实长什么样。
举个例子:
- 你让它修结算页 Bug,但没给最新错误栈 → 模型只能蒙
- 你让它重构用户模块,但没给数据契约 → 它猜错业务逻辑
- 你让它接第三方 API,却没给官方文档 → 它凭记忆胡乱生成
结果:蒙对了,你觉得它聪明;蒙错了,你又觉得它不靠谱。问题其实都在输入层。
WARNING
⚠️ 真实痛点
开发者的信息分散在 Jira(需求)、Notion(文档)、Git(代码)、终端(日志)里。AI 编程最大的瓶颈不是模型能力,而是如何把这些分散的信息无损地输入给大模型。
1.1 怎么理解 Context 工程?
你就把它想成带新同事接盘一个陌生项目。
如果你只跟他说“这个结算流程帮我查一下”,他多半会一脸懵。你得给他目录结构、问题现象、相关日志、最近变更、接口文档、禁改红线。他不是不聪明,只是没背景。
模型也是一样。Context 工程的本质,不是往对话框里狂塞信息,而是给模型构造一个最小但完整的工作现场。
1.2 上下文不只是文字
很多人以为"上下文"就是把代码文件贴给 AI。太狭隘了。上下文至少包含 5 类信息:
| 上下文类型 | 具体内容 | 来源 |
|---|---|---|
| 文件内容 | 源码、配置、文档 | IDE / Git |
| 运行日志 | 错误堆栈、构建输出 | 终端 / CI |
| 命令结果 | 测试报告、lint 输出、依赖树 | CLI 工具 |
| 规范约束 | 编码规范、架构约束、业务规则 | CLAUDE.md / 规则文件 |
| 历史决策 | 为什么选 A 不选 B、已知坑点 | 团队知识库 |
1.3 决定结果质量的不是模型,是信息
同一个 Prompt,喂给它 3 行报错日志 vs 喂给它完整的错误栈 + 相关源码 + 数据库 Schema——产出质量的差距是数量级的。
INFO
"Garbage in, garbage out" 在 AI 编程中同样适用,甚至更加残酷——信息过多会淹没关键点,信息过少会导致误判。上下文工程的核心,就是在"过多"和"过少"之间找到精准的平衡。
来看一个特别典型的排错场景。需求是修复支付回调重复入账。
❌ 只给 Prompt
支付回调重复入账了,
帮我分析原因并修复。✅ 给完整上下文
支付回调重复入账:
1. 附最近 3 次失败请求日志
2. 附 `payment_webhook.ts` 和幂等表 schema
3. 附支付平台重试策略说明
4. 说明:不能改金额计算逻辑只给一句 Prompt 时,模型特别容易把锅甩给“没做幂等”,然后建议你加 Redis 锁。可一旦你把回调重试策略和数据库唯一索引放进去,它才发现根因其实是业务方先写表、后校验签名,异常回滚路径断了。
这就是 L1 现象层最直白的一件事:同样的模型、同样的 Prompt,上下文一变,答案质量能直接从“像那么回事”掉到“完全跑偏”。
既然上下文这么关键,下一步就得把它拆开。你不能再笼统地说“多给点上下文”,而要知道上下文到底分哪几层。
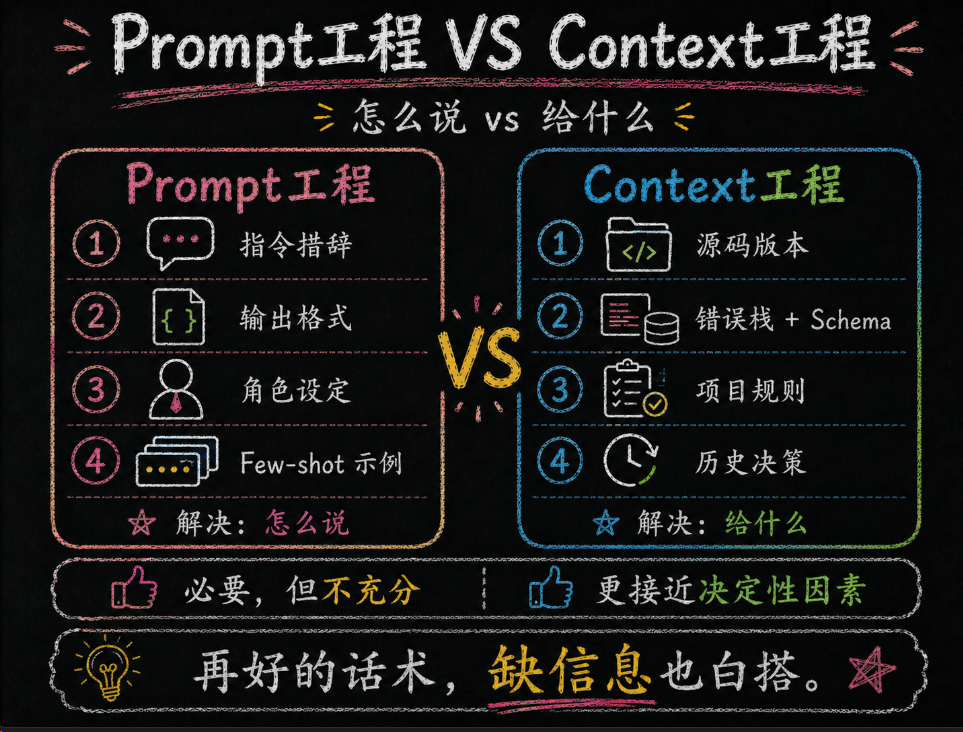
Prompt 工程解决"怎么说",上下文工程解决"给什么"——后者才是决定性因素
二、核心上下文维度的拆解与供给
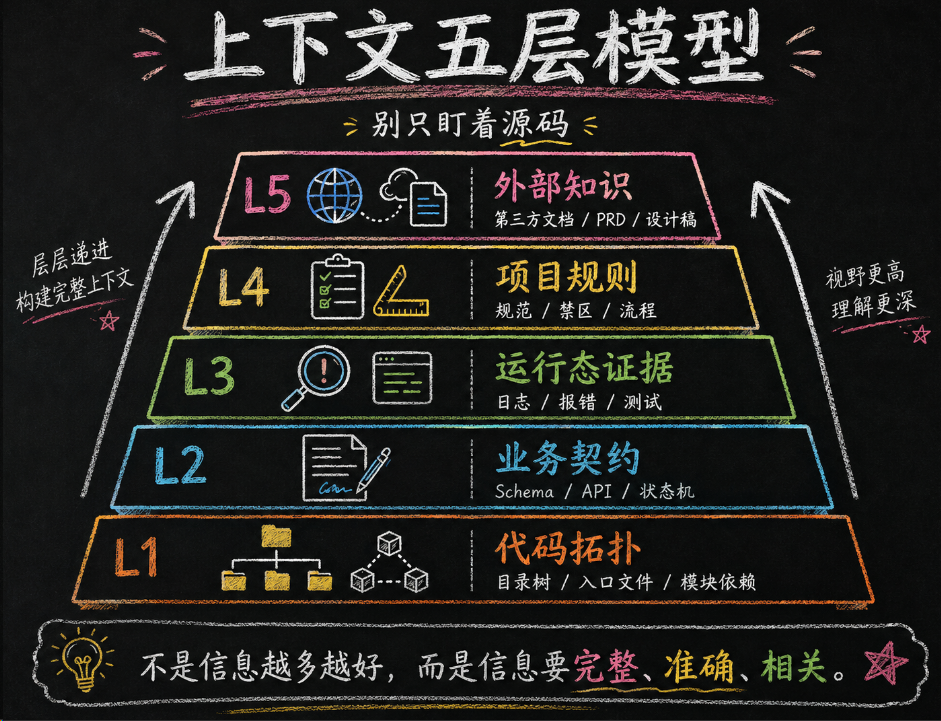
很多人一提“给上下文”,脑子里只有源码。这就像医生看病只看化验单,不看病史、不看影像、不听主诉。信息不是没有,是偏科了。
在 Vibe Coding 里,我们把上下文拆成五层:
- 代码拓扑:项目目录、入口文件、关键模块和依赖关系
- 业务契约:数据库 schema、API 契约、状态机、权限规则
- 运行态证据:日志、异常栈、失败测试、构建报错
- 项目规则:CLAUDE.md、AGENTS.md、代码规范、禁止事项
- 外部知识:第三方 API 文档、设计稿、PRD、厂商限制
2.1 代码拓扑上下文
这是最基础的一层——让模型理解你的项目长什么样。就像你去一个新公司,第一件事不是写代码,而是先看目录结构、找入口文件、理清模块关系。读者很容易忽略这一层,因为它看起来不像业务逻辑那么“有内容”,但它决定模型能不能先找到对的地方。
必须供给的信息:
- 目录树:让模型理解项目组织方式
- 入口文件:理解应用启动流程
- 关键模块:核心业务逻辑所在位置
- 模块依赖图:谁依赖谁、导出关系
示例:
# Skeleton Extraction: 列出类名和函数签名
project_map = [
"UserService: findById(id), create(dto), update(id,dto), delete(id)",
"PaymentWebhook: handleCallback(payload)",
"OrderService: createOrder(dto), cancelOrder(id)"
]代码拓扑像商场导览图。你要找一家店,先得知道它在几楼哪个区。别一上来就让模型扎进 500 行函数体里游泳,先给它一张平面图。
INFO
✅ 最佳实践
先给目录树让 AI 建立"地图",再给入口文件让它理解"入口",最后按需给具体模块的源码。这就是"先给地图,再给地形"的策略。
2.2 业务契约上下文
代码拓扑告诉 AI "项目长什么样",业务契约告诉 AI "业务规则是什么"。没有这层上下文,AI 写出的代码可能语法正确但业务逻辑完全错误。所以模型在通用代码上通常挺强,在“你们团队自己约定的规则”上经常最危险。因为这部分训练语料里没有,它只能猜。
这层常见信息包括:
- 数据库字段含义、唯一索引、软删规则
- API 输入输出结构、状态码语义
- 幂等键、金额精度、权限隔离规则
- 状态机:哪些状态能跳,哪些绝对不能跳
这也是为什么支付、权限、风控、结算这种模块最容易“看起来写对了,实际上不能上”。模型不是不会写代码,而是不知道你业务里的红线是什么。
❌ 没有业务契约
# AI 的理解
"帮我写一个用户注册接口"
# AI 猜测:用户表有哪些字段?
# AI 猜测:密码怎么加密?
# AI 猜测:需要邮箱验证吗?
# → 产出:能跑但业务逻辑全错✅ 有业务契约
# AI 的理解
"帮我写一个用户注册接口"
+ Schema: users 表 (id, email, password_hash, ...)
+ API: POST /api/users, 201/400/409
+ 类型: CreateUserDTO, UserResponse
# → 产出:业务逻辑精确匹配2.3 运行状态上下文
修 Bug 时最关键的一层。AI 需要知道"现在出了什么问题",而不是让你口述"好像有个报错"。日志、失败测试、终端报错这些东西,本质上是现场录像。你不提供现场录像,模型就只能靠回忆和推理写侦探小说。
一般包括以下信息:
- 终端错误栈(Stack Trace):完整的报错信息,不是截取的片段
- 浏览器 Console 报错:前端问题的第一手证据
- 测试失败报告:哪个测试挂了、期望值 vs 实际值
- 构建日志:编译错误、警告信息
# 一个更靠谱的错误上下文包
- 失败测试:`pnpm test checkout --filter timeout`
- 堆栈:`TypeError: cannot read properties of undefined`
- 最近变更:将 `couponRules` 从 sync 改成 async
- 现象:只在生产环境复现,本地无法稳定重现这段信息的价值,远比“帮我分析一下为什么报错”高得多。因为它已经把问题缩到具体链路、具体症状、具体变化点了。
DANGER
❌ 常见误区
很多人只截报错的第一行给 AI,比如 "TypeError: Cannot read property 'map' of undefined"。但关键信息往往在堆栈的中间——是哪个文件的哪一行调用了 .map()?那个变量为什么是 undefined?完整堆栈才是有效上下文。
2.4 项目规则上下文
这层上下文解决的是"风格一致性"问题。没有它,AI 每次生成的代码风格都不一样——今天用axios,明天用fetch;今天用 class,明天用函数式。
一般包括以下信息:
- CLAUDE.md / AGENTS.md / Cursor Rules:项目级规则文件
- 技术栈说明:用什么框架、什么版本
- 编码规范:命名约定、文件组织方式
- 禁止事项:不允许用的库、不允许写的模式
2.5 外部知识上下文
AI 的训练数据有截止日期,而且它对第三方 API 的记忆可能已经过时。这时候你需要主动把最新文档喂给它。
一般包括以下信息:
- 第三方 API 文档:不是让模型凭记忆猜测接口参数
- 设计稿截图或 Figma 链接:前端开发需要视觉参考
- 需求文档与 PRD:产品需求的完整描述
WARNING
⚠️ 供应链投毒风险
不要随便从网上复制 API 文档喂给 AI——恶意构造的文档可能包含"提示注入"攻击,让 AI 执行危险操作。只使用官方文档或可信来源。
项目规则解决的是“能不能这么做”,外部知识解决的是“世界现在是不是这样”。
比如说:
AGENTS.md告诉模型能不能删文件、能不能改数据库、做完要不要跑测试- 第三方 SDK 文档告诉模型这个参数到底还存不存在,重试语义有没有变
OpenAI 的 File Search 官方文档把这件事说得很直白:不要指望模型凭“内在知识”记住你的私有资料,应该把文件放进向量存储,让模型先检索再回答。
五层拆开以后,你会发现真正的难点不是“有没有上下文”,而是“如何裁剪”。因为现实项目很少缺信息,缺的是信息管理。
三、应对长上下文的精准裁剪策略
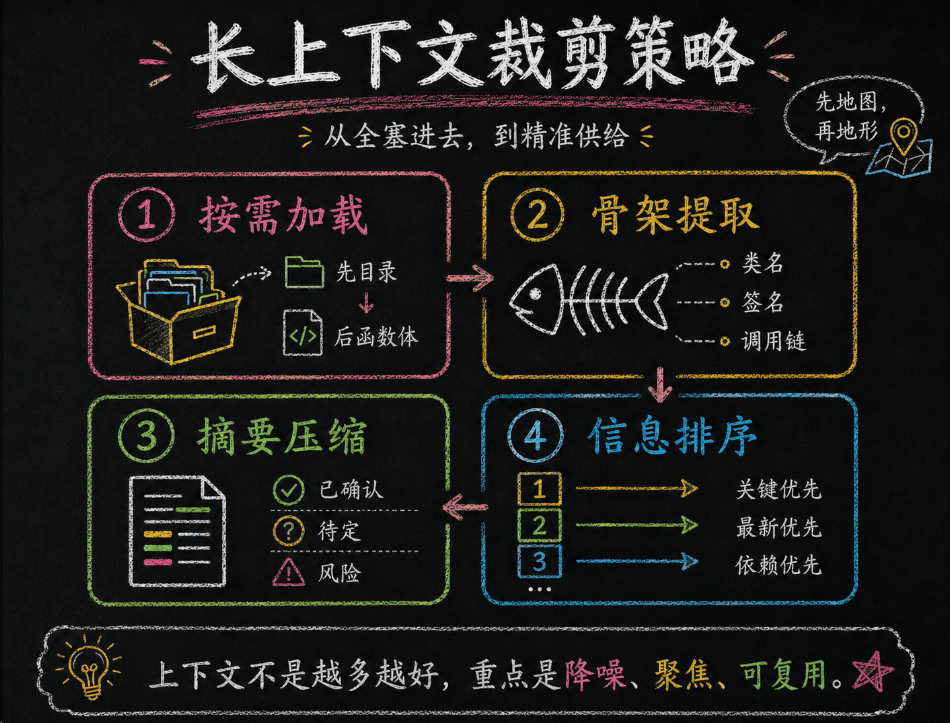
知道了该给什么信息,下一个问题是:信息太多怎么办?现在的模型上下文窗口动辄 128K、200K Token,但"能装下"不等于"能用好"——信息过多会淹没关键点,导致模型注意力分散。
你需要像编辑一样裁剪上下文,只保留最有价值的部分。
很多人看到“模型支持超长上下文”,就产生一种错觉:能塞进去,就等于能理解好。这个错觉很贵,贵在成本,贵在时间,更贵在误判。
Anthropic 在 Long Context Tips 官方文档里提到两点特别值得记住:
- 长文档内容应该尽量放在前面,query 放在后面
- 复杂多文档输入里,把 query 放到末尾,在测试中能把回答质量拉高到最多 30%
这说明一个事实:上下文不是垃圾桶,顺序本身就是提示的一部分。
WARNING
⚠️ “全仓喂模型”是低级反模式
把整个 src、所有日志、所有 PRD 一口气塞进去,看起来很勤奋,实际等于把重点埋了。模型最怕的不是信息少,而是关键信息被噪音淹没。
四个最值钱的裁剪策略
- 按需加载:先给目录和签名,确认模块后再补函数体
- 骨架提取:先给类名、接口、调用链,再补实现
- 摘要压缩:把上一轮结论压成“已确认 / 待定 / 风险”
- 信息排序:把新鲜、关键、被依赖的信息放在前面
3.1 按需加载(Lazy Loading)
这是最基本的原则:拒绝将整个src文件夹丢入会话。按模块、按任务给上下文,用完即清理。
想象你在做菜——你不会把冰箱里所有食材都搬到灶台上,而是按菜谱取用。AI 编程也一样:修用户模块的 Bug,就只给用户模块的上下文,不需要把支付模块也塞进去。
❌ 全量加载
# 把整个项目丢给 AI
@src (包含 200+ 文件)
# 结果:
# - Token 消耗巨大
# - 关键信息被淹没
# - AI 注意力分散
# - 输出质量显著下降✅ 按需加载
# 只给相关模块
@src/users/user.service.ts
@src/users/user.model.ts
@src/db/schema.prisma
# 结果:
# - Token 消耗降低 80%
# - 关键信息突出
# - AI 聚焦核心逻辑
# - 输出质量显著提升3.2 骨架提取(Skeleton Extraction)
先给 AI 看"骨架"(类名、函数签名、类型定义),等确认要改哪个部分,再拉取具体的函数体。这就是"先给地图,再给地形"。
# 第一步:给骨架(让 AI 浏览全局)
# src/users/user.service.ts
export class UserService {
async findById(id: string): Promise // L23
async create(dto: CreateUserDTO): Promise // L45
async update(id: string, dto: UpdateDTO): Promise // L67
async delete(id: string): Promise // L89
}
# 第二步:AI 确认要改 findById → 再给 L23-L44 的完整实现3.3 摘要机制(Summarization)
当对话历史变得冗长时,让 AI 自动总结"前面的核心结论",生成一个记忆压缩包,然后清空冗长的对话历史。
推荐的摘要格式:
📋 上下文摘要
─────────────────────
✅ 已确认:使用 PostgreSQL + Prisma ORM
✅ 已确认:API 遵循 RESTful 规范
✅ 已确认:认证用 JWT + Refresh Token
⏳ 待定:缓存策略选 Redis 还是 Memcached
⚠️ 风险:users 表的 email 字段缺少唯一索引
─────────────────────INFO
💡 实操技巧
在长会话的中途,主动对 AI 说:"请总结我们到目前为止确认的所有决策和待定事项,格式为:已确认 / 待定 / 风险。"然后把这段摘要带到新会话中继续工作。
3.4 信息排序策略
信息的顺序直接影响模型的注意力分配。模型对上下文开头和结尾的信息关注度最高(这就是所谓的"首因效应"和"近因效应"),中间的信息最容易被忽略。
| 排序策略 | 适用场景 | 示例 |
|---|---|---|
| 按重要性 | 通用场景 | 核心约束放最前面,辅助信息放后面 |
| 按时间 | 调试/排错 | 最新的错误日志放前面,历史日志放后面 |
| 按依赖关系 | 架构设计 | 被依赖的模块放前面,依赖它的放后面 |
3.5 检索不是可选配件,是上下文工程的外接硬盘
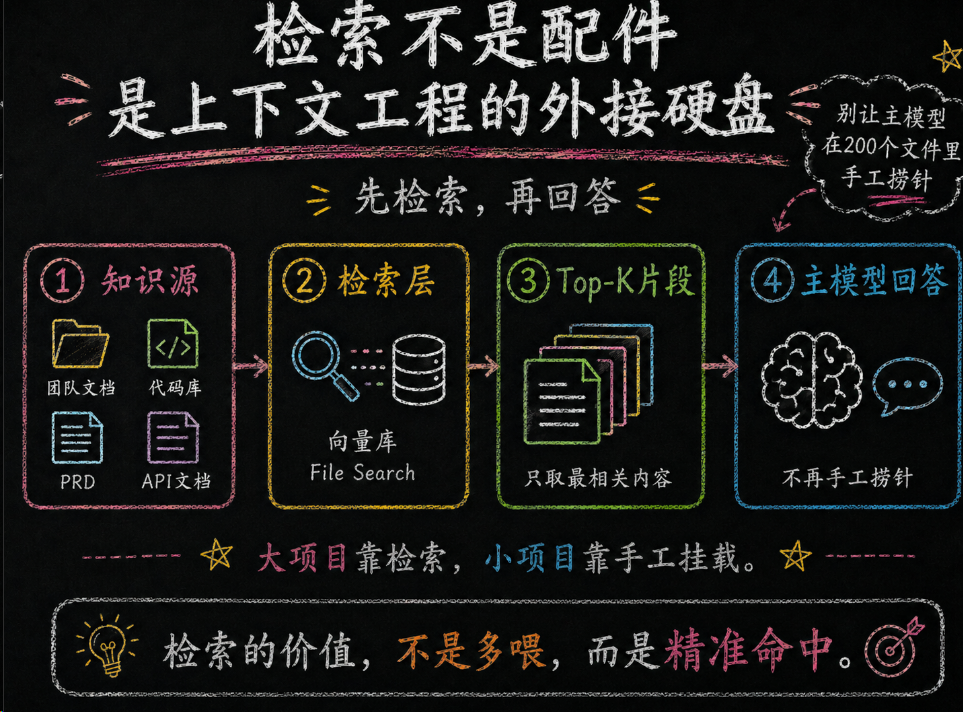
一旦项目开始变大,手工挂载文件会很快碰到上限。这时候你就该上检索层了。
OpenAI 的 File Search 官方工具本质上做的事很简单:把文件放进向量存储,让模型先做语义检索,再把相关片段拿出来回答。这样你不必每次都把整包文档塞进请求里。
✅ 实现层思路
当任务是“在团队知识库里找与当前 Bug 最相关的文档片段”时,优先用检索工具把候选内容缩成 Top-K,再喂给主模型。别让主模型在 200 个文件里手工捞针。
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5.4",
input="支付回调幂等处理规则是什么?",
tools=[{
"type": "file_search",
"vector_store_ids": ["vs_team_knowledge"]
}],
include=["file_search_call.results"]
)裁剪问题说完了,下一步就该算账了。因为只会裁还不够,你还得知道哪些上下文值得缓存,缓存后究竟能省多少钱、快多少。
四、Prompt Caching 的原理与成本账
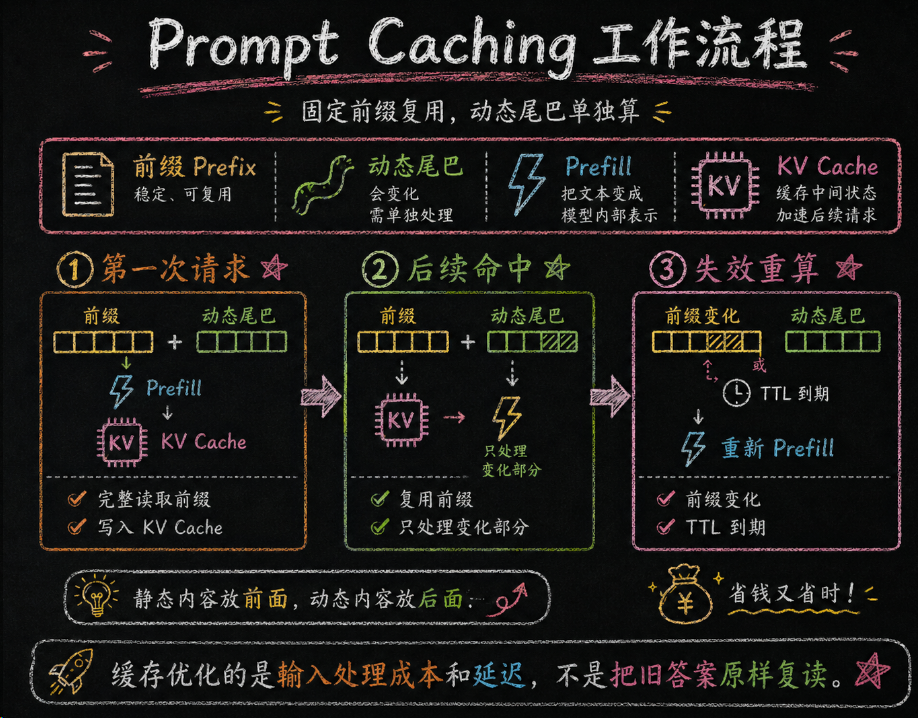
缓存这件事,说人话就是:别每次都让模型把同一段静态前缀重新读一遍。项目规则、工具定义、Few-shot 示例、长文档背景,这些东西如果 90% 的时间都不变,那你每轮都让模型重新 prefill 一次,等于把钱和时间一起烧在重复劳动上。
但这里有个特别容易混淆的点:Prompt Caching 不是你在应用层做 Redis,也不是把上一次回答整个搬回来。它缓存的是前缀被模型“读完以后”形成的内部中间态,最关键的就是 attention 里的 KV cache,也就是 Key/Value tensors。
INFO
💡 这一节先把三个概念分开
应用层缓存是“同样的问题直接复用结果”;Prompt Caching是“同样的前缀不再重新 prefill”;模型输出依然是这次实时算出来的。也就是说,缓存优化的是输入处理阶段,不是把旧答案原样复读。
4.1 先把基础概念钉牢:前缀、prefill、KV cache、TTL 到底是什么
很多人一听“缓存”,脑子里会自动联想到 Web 缓存,觉得是不是“上一次的回答直接拿来复用”。不是。Prompt Caching 不会把旧答案原封不动塞回来,模型每次输出仍然是重新生成的。 它复用的是模型在读入前缀时产生的中间计算结果,所以省下来的主要是输入处理时间和输入成本。
生活里很好理解。你去公司楼下咖啡店点固定套餐,店员已经记住你“冰美式、少冰、不加糖”这一串前缀,下次你只需要补一句“今天再加一个牛角包”。Prompt Caching 干的就是这件事:把固定前缀记熟,让本轮只处理变化量。
- prefix(前缀):请求前半段里稳定不变的部分,比如系统提示、工具定义、项目规则、固定示例。
- dynamic tail(动态尾巴):每次都可能变化的部分,比如当前用户问题、本轮 diff、最新日志。
- prefill:模型先把输入完整读一遍、建立上下文表示的过程。长输入贵,通常就是贵在这里。
- KV cache:prefill 之后留下来的中间表示。命中缓存,本质上是在复用这部分结果。
- TTL:缓存能活多久。过了这个时间,命中率就会下降,甚至完全失效。
- cache hit / miss:命中就复用,不命中就重读并重建缓存。
WARNING
⚠️ 一个很关键的边界
Prompt Caching 不会改变最终回答的逻辑含义。OpenAI 官方明确写了:缓存不会影响输出 token 的生成结果,影响的是前缀处理的成本和延迟。也就是说,它是性能优化,不是推理增强。
4.1.1 缓存到底是怎么发生的:把平台内部过程想成三步
如果只停留在“前缀能复用”这句话,还是容易发虚,因为不知道缓存到底是在什么时候写进去、什么时候读出来。把内部过程压成三步,就不容易乱了。
- 第一次请求到来:平台先读取整段输入,发现前半段有一大块稳定前缀,于是完整做一次 prefill,并把这段前缀对应的中间状态记下来。这一步最贵,因为模型是真的从头读到了尾。
- 第二次相似请求到来:平台先检查这次请求前缀是不是和上次足够一致。如果一致,就直接复用上次记下来的中间状态,跳过大段重复 prefill,只重新处理这次变化的尾部内容。
- 前缀变化或缓存过期:只要前缀关键部分变了,或者 TTL 到了,平台就不能继续复用旧缓存,只能重新读、重新算、重新写一份新缓存。
你可以把它理解成“先做一遍重活,后面尽量别重复做”。所以缓存的收益,本质上取决于两件事:这段重活够不够大,以及后面能不能重复利用很多次。前缀越长、复用次数越多,缓存越值钱。
| 阶段 | 平台在做什么 | 你会看到的结果 |
|---|---|---|
| 第一次请求 | 完整 prefill,并写入可复用的前缀中间状态 | 成本高一些,TTFT 也通常更长 |
| 后续命中请求 | 直接读取缓存,跳过大段重复计算 | 输入成本下降,TTFT 往往更快 |
| 缓存失效请求 | 因为前缀变化或 TTL 到期,重新计算并重写缓存 | 表现会接近第一次请求 |
这也是为什么很多团队会误判缓存效果。它不是“开了以后所有请求都立刻变快”,而是“同一类请求跑到第二次、第三次以后,收益才开始明显出现”。如果你的工作流本来就没有复用,或者每轮都把前缀改掉,缓存当然也发挥不出来。
4.2 哪些内容值得缓存,哪些不值得

判断标准其实不复杂,核心就三条:变化慢、复用高、尽量放在前面。这三条同时满足,缓存价值通常就很高。反过来,变化快、只用一次、还和当前问题强绑定的内容,就不应该硬塞进缓存区。
| 内容类型 | 适不适合缓存 | 原因 |
|---|---|---|
| 系统提示、角色设定、团队规则 | 适合 | 长期稳定,很多请求都会反复复用 |
| 工具定义、JSON Schema、输出格式约束 | 适合 | 通常很长,而且变动频率很低 |
| Few-shot 示例、固定背景文档摘要 | 适合 | 属于高成本前缀,最能体现缓存价值 |
| 当前用户问题、本轮 diff、最新日志 | 不适合 | 几乎每轮都在变,放进去只会频繁 bust cache |
| 时间戳、trace id、实时状态快照 | 不适合 | 变化太快,和缓存的“稳定前缀”目标正冲突 |
如果你还不确定,最简单的落地判断法就是问自己一句:“这段内容下一轮还会不会原样再用一次?”如果答案经常是“会”,那它大概率值得进入缓存前缀;如果答案经常是“不会”,那就别勉强。
✅ 更容易命中的组织方式
系统提示
团队规则
工具定义
结构化输出 schema
Few-shot 示例
文档摘要
当前用户问题❌ 容易把缓存打散的组织方式
当前时间戳
当前用户问题
本轮 diff
系统提示
工具定义
Few-shot 示例
文档摘要看到这里,你应该已经能明白一件事:缓存不是一个单独的“开关优化”,它要求你先把上下文摆整齐。上下文越乱,缓存收益越低。
4.3 进阶理解:OpenAI 和 Anthropic 都能缓存,但工作方式不一样
两家平台的共同点很明确:都要求你把静态内容放前面,把动态内容放后面。但它们的设计哲学不同。OpenAI 更像“自动路由 + 自动复用”,Anthropic 更像“你来决定缓存断点放哪”。 这点不搞清楚,后面调命中率时会一直拧巴。
4.3.1 OpenAI:自动缓存,重点是前缀稳定
按 OpenAI 官方 Prompt Caching 文档,满足缓存条件后,请求会自动参与缓存,不需要你手动给每个段落打断点。它的关键点可以压成四句人话:
- 请求达到 1024 tokens 以上,才有机会命中缓存。
- 只有前缀精确匹配,缓存才有意义,所以静态内容必须前置。
- 系统会根据前缀哈希做路由,再去对应机器上查缓存。
- 如果你持续复用长前缀,可以用
prompt_cache_key帮系统更稳定地路由。
这里最容易被忽略的是“路由”这件事。很多人以为缓存就是一个抽象的全局黑盒,其实 OpenAI 文档写得很直白:请求会先按前缀哈希路由到最近处理过相同前缀的机器,再判断能不能命中。所以你不只是要“内容一样”,还要尽量“让相同前缀持续出现”。
观测入口也很明确,看响应里的usage.prompt_tokens_details.cached_tokens。这个字段越大,说明本轮复用掉的前缀越多。如果它长期接近 0,就别再猜“是不是缓存失效了”,直接回去检查前缀是不是被你改乱了。
4.3.2 Anthropic:显式断点,重点是断点位置合理
Anthropic 的思路更工程化一些。它允许你用cache_control明确标记“到这里为止的前缀值得缓存”。这意味着你不只是在想“哪些内容稳定”,还要进一步想“稳定内容的边界切在哪最合理”。
Anthropic 官方文档里有三个特别关键的点:
- 缓存前缀按
tools → system → messages的顺序组织,这个顺序会直接影响命中。 - 单个显式断点通常就够用,系统会往前回看大约 20 个内容块,寻找最长可命中的前缀。
- 最多可以定义 4 个断点;如果内容块很多,且关键静态内容离最终断点太远,就要考虑增加断点。
它的直觉很好理解:OpenAI 更像“只要你前缀稳定,我尽量替你命中”;Anthropic 更像“你把断点切准,我再帮你复用”。所以 Anthropic 最常见的错误不是“忘了开缓存”,而是把断点打在每轮都会变化的块上,结果每次都在写缓存,却几乎读不到缓存。
DANGER
🚨 Anthropic 最典型的误用
把带时间戳、trace id、当前用户问题的内容块标成cache_control。这样看上去像是“开了缓存”,实际上每轮都在生成一个新前缀,读缓存的概率非常低,反而会让你误以为平台缓存不稳定。
Anthropic 的默认 TTL 是 5 分钟,也支持 1 小时 TTL。不同 Claude 模型的最小可缓存长度并不完全一样,官方文档里常见门槛是 1024 或 2048 tokens。这个细节不要死记,实战里直接以你调用的模型文档为准。
4.3.3 一张表记住差异,不用混着背
| 维度 | OpenAI | Anthropic |
|---|---|---|
| 启用方式 | 自动参与缓存 | 通过cache_control指定缓存边界 |
| 核心关注点 | 前缀是否稳定且完全匹配 | 断点是否切在稳定内容之后 |
| 保留策略 | 默认内存缓存,部分模型支持更长保留 | 默认 5 分钟,可选 1 小时 |
| 观测字段 | cached_tokens | cache_read_input_tokens/ cache_creation_input_tokens |
| 最常见踩坑 | 前缀里混入变化内容,导致精确匹配失败 | 断点打在易变块上,导致只写不读 |
4.4 成本账要这样算:不是“感觉省”,而是能拿计算器复算

讲缓存如果只讲概念,不讲账,很容易落回“听起来很高级,但我不知道值不值得做”。所以这里我们直接按工程账来算。思路很简单:
- 不缓存时:每轮都按完整输入计费。
- 缓存命中时:稳定前缀按缓存输入价计算,动态尾巴按普通输入价计算。
- 如果平台区分“写缓存”和“读缓存”,就把首轮写入成本和后续读取成本拆开算。
沿用一个很常见的项目场景:100 次相似请求,每次都有 120K tokens 的静态前缀,外加 2K tokens 的动态尾巴。按文首版本声明对应的 OpenAI 官方价格页,若使用gpt-5.1,普通输入价是 $1.25 / 1M tokens,缓存输入价是 $0.125 / 1M tokens。
| 方案 | 计算方式 | 估算成本 |
|---|---|---|
| 完全不缓存 | 100 × (120K + 2K) × 普通输入价 | 约 $15.25 |
| 只缓存静态前缀 | 首轮完整输入 + 99 轮缓存前缀 + 99 轮动态尾巴 | 约 $1.89 |
这就是为什么缓存不是“小优化”。在长前缀、强复用的工作流里,它可能直接决定你的成本结构。对编程 Agent、代码审查、长文档问答、工作流编排这种场景来说,这种差距是能从账单上直接看见的。
而且缓存省的不只是钱。长前缀被复用后,模型不需要每次都完整 prefill,TTFT(Time to First Token,首字返回时间)通常也会明显缩短。对交互式产品来说,这个体验提升很关键,因为用户最敏感的往往不是总耗时,而是“为什么它半天都不开始说话”。
4.5 需要关注的点:命中率为什么掉
项目里缓存效果不好,通常不是“平台缓存有 bug”,而是前缀管理出了问题。下面这些场景,都是工程里最常见的cache bust来源:
✅ 有利于命中的做法
- 固定工具定义顺序
- 固定 JSON key 顺序
- 把系统规则放在最前面
- 把图像 detail 参数保持一致
- 把 schema 版本化管理
- 动态信息统一放到最后❌ 最容易 bust cache 的做法
- 在前缀里插入时间戳
- 工具列表每轮重排
- JSON 序列化顺序不稳定
- 中途改 schema 或 tool_choice
- 同一张图换了 detail 参数
- 把本轮 diff 混进静态规则里这里有一个很值得注意的小坑:很多缓存 miss 不是“大改了 Prompt”,而是“改了一点点你没注意到的格式”。 比如 JSON key 顺序漂移、工具定义顺序变化、系统提示里多了一行调试标记,这些看上去都很小,但对“前缀精确匹配”来说都是实打实的破坏。
WARNING
⚠️ 高级优化不要只看平均成本
真正值得监控的至少有三项:缓存命中 token 占比、首字返回时间 TTFT、命中失败后的原因分布。只盯总 token 很容易把“前缀很长但命中很好”的健康场景,误判成“成本必炸”的异常场景。
4.6 详细实现:前缀缓存不是“把 Prompt 变长”,而是把静态区单独拆出来

前面几节讲的是原理,这一节只做一件事:把“怎么缓存前缀”写成一套你可以照着落地的实现流程。很多人写了半天缓存,其实只是把 Prompt 写得更长,并没有真的把前缀和动态内容拆开。结果看上去“开了缓存”,实际命中率很低。
所以目的很明确:把一条请求拆成静态前缀和动态尾巴两部分,让平台反复看到几乎相同的前缀,只对每轮变化的内容重新计算。无论你用 OpenAI 还是 Anthropic,真正稳定的实现顺序都应该是下面这四步:
- 先定义长期稳定的前缀内容:规则、工具定义、schema、Few-shot、文档摘要。
- 再单独拼接每轮变化的尾巴:当前问题、最新 diff、最新日志、实时状态。
- 发请求时保持前缀顺序稳定,不要把动态内容插进前缀中间。
- 最后看 usage 字段,确认缓存读到了,而不是只写了没读。
4.6.1 先把请求拆成两段:static_prefix和dynamic_tail
如果你在代码层面都没有把这两段拆开,后面几乎不可能把缓存做好。因为一旦所有内容都混在一个字符串里,时间戳、trace id、当前问题这些动态字段就很容易混进前缀,把命中率打散。
STATIC_RULES = """
你是团队代码审查助手。
你必须按“风险级别、影响范围、修复建议”输出。
禁止臆测未提供的运行时事实。
"""
STATIC_TOOLS = """
可用工具:
1. diff_reader
2. test_summary
3. log_lookup
"""
STATIC_EXAMPLES = """
示例 1:发现空指针风险时,先定位触发路径,再给出修复建议。
示例 2:发现事务边界错误时,明确指出回滚风险。
"""
def build_static_prefix():
return "\\n\\n".join([
STATIC_RULES,
STATIC_TOOLS,
STATIC_EXAMPLES,
])
def build_dynamic_tail(question, diff_summary, log_excerpt):
return f\"\"\"本轮任务:{question}
本轮 diff 摘要:
{diff_summary}
最新日志摘录:
{log_excerpt}
\"\"\"这段代码里真正关键的点不是“有没有封装成函数”,而是静态区和动态区从一开始就是分开的。只有这样,你才能保证每次请求进来时,前缀部分尽量不动,尾巴部分自由变化。
WARNING
⚠️ 一个很常见的误写
不要把“当前时间”“当前用户问题”“本轮 diff”“最新 trace id”先拼进大字符串,再把这整串内容当成前缀发出去。这样表面上是一个完整 prompt,实际上缓存看到的是“每轮都不一样的新前缀”。
4.6.2 OpenAI:自动缓存,但前缀稳定性必须由你自己负责
OpenAI 侧的好处是不用手动给每个 block 打断点,但坏处是很多人会误以为“既然是自动缓存,我就不用管前缀结构了”。恰好相反。OpenAI 的自动缓存,最依赖你把稳定前缀组织好。
from openai import OpenAI
client = OpenAI()
STATIC_RULES = """
你是团队代码审查助手。
输出格式固定为:
1. 风险级别
2. 触发条件
3. 影响范围
4. 修复建议
"""
STATIC_SCHEMA = """
输出必须是 JSON:
{
"risk_level": "...",
"root_cause": "...",
"fix": "..."
}
"""
STATIC_EXAMPLES = """
示例:
输入:checkout 里对库存扣减没有加锁
输出:指出并发超卖风险、触发条件和修复建议
"""
def build_prefix():
return "\\n\\n".join([
STATIC_RULES,
STATIC_SCHEMA,
STATIC_EXAMPLES,
])
def ask_review(question, diff_summary):
response = client.responses.create(
model="gpt-5.1",
input=[
{
"role": "system",
"content": [
{
"type": "input_text",
"text": build_prefix()
}
]
},
{
"role": "user",
"content": [
{
"type": "input_text",
"text": f"本轮问题:{question}\\n\\n本轮 diff:\\n{diff_summary}"
}
]
}
],
prompt_cache_key="review-agent-v1",
prompt_cache_retention="24h"
)
return response
first = ask_review(
"检查 checkout 改动的风险点",
"新增库存扣减逻辑,但没有看到锁或事务边界。"
)
second = ask_review(
"继续检查这次 checkout 改动的并发问题",
"同一套规则和 schema,不同的是本轮问题和 diff 摘要。"
)
print(first.usage.prompt_tokens_details.cached_tokens)
print(second.usage.prompt_tokens_details.cached_tokens)这段实现要点有四个,最好逐条记住:
- 前缀单独收口:规则、schema、示例都放在
build_prefix()里,保证它们顺序固定。 - 动态内容只放尾部:当前问题和本轮 diff 只出现在 user 消息里,不混进 system 前缀。
- 工作流使用稳定 key:同一类任务持续复用同一个
prompt_cache_key,帮助平台更稳定地做前缀路由。 - 看第二轮而不是只看第一轮:第一轮更多是在“写缓存”,第二轮开始才更容易看到
cached_tokens明显上升。
所以 OpenAI 这边“怎么缓存前缀”的本质不是多传一个参数,而是把长期稳定内容集中放前面,再让后续请求反复复用这套前缀。参数只是触发器,前缀结构才是主体。
4.6.3 Anthropic:显式缓存前缀,重点是把断点落在静态区末尾
Anthropic 更适合把“缓存哪一段前缀”写得非常明确。你可以把静态区拆成多个 block,然后把cache_control放在最后一个稳定 block上,等于告诉平台:“到这里为止,前缀已经稳定,可以缓存了;后面才是每轮变化的内容。”
from anthropic import Anthropic
client = Anthropic()
STATIC_BLOCKS = [
{
"type": "text",
"text": "你是团队故障排查助手。输出时先给结论,再给证据。"
},
{
"type": "text",
"text": "固定规则:不要臆测数据库状态;没有日志证据就明确写“待验证”。"
},
{
"type": "text",
"text": "Few-shot 示例:遇到超时问题时,先看连接池,再看慢 SQL,再看下游服务。",
"cache_control": {
"type": "ephemeral",
"ttl": "1h"
}
}
]
def ask_debug(question, log_excerpt):
response = client.messages.create(
model="claude-sonnet-4",
max_tokens=1024,
system=STATIC_BLOCKS,
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": f"本轮问题:{question}\\n\\n最新日志:\\n{log_excerpt}"
}
]
}
]
)
return response
resp = ask_debug(
"解释这次 checkout 超时错误",
"日志显示请求堆积在 inventory service,连接池等待时间升高。"
)
print(resp.usage.cache_read_input_tokens)
print(resp.usage.cache_creation_input_tokens)这里的关键动作不是“加了cache_control”,而是把它放在静态区最后一个 block 上。这样平台缓存的是整段稳定前缀,而不是把本轮问题、日志摘录这些每次都变的内容也一起绑进去。
你可以把 Anthropic 的实现想成一把刀:前面一整段是固定前缀,刀落下去的地方就是缓存边界。刀落得准,后面每一轮都会更省;刀落到动态区里,缓存就会一直重写,收益很差。
五、项目级规则体系
很多团队做 Context 工程,做到后面会发现:不是“模型不知道”,而是“模型没人管”。
这时候规则文件就像高速公路护栏。它不负责开车,但它负责让车别冲下去。
5.1 规则文件为什么值得单独建
CLAUDE.md、AGENTS.md、.cursorrules这类文件,最大的价值不是写理念,而是写可执行限制:
- 统一包管理器和常用命令
- 哪些目录允许改,哪些目录禁止碰
- 任务执行流程:先计划、再执行、再验证
- 验收标准:要不要测试、要不要 lint、要不要附风险说明
示例:
# 项目简介
支付中台,Node.js + PostgreSQL
# 允许做的事
- 读写 `src/payments/*`
- 运行测试和 lint
- 输出风险与假设
# 禁止做的事
- 不允许直接改生产配置
- 不允许删除迁移文件
- 不允许修改金额计算规则
# 执行流程
1. 先给计划
2. 再执行补丁
3. 收尾给验证结果5.2 规则设计原则
写规则文件不是写小作文,而是写可执行的指令。三个"只"原则:
- 只写必须的——不说废话,每条规则都有存在的理由
- 只写可执行的——AI 能直接遵循的,而不是空泛的口号
- 只写会定期 review 的——过时的规则比没有规则更危险
❌ 空泛口号
# 项目规范
写高质量的代码。
注意代码风格一致性。
保持简洁。
做好错误处理。
# → AI 看了等于没看
# → 每条都无法直接执行✅ 可执行指令
# 项目规范
- 使用 pnpm,禁止 npm/yarn
- 组件用函数式 + hooks,禁止 class
- API 路由统一放在 src/api/ 下
- 错误处理用 Result 模式
- 数据库查询必须带超时(3s)
- 禁止使用 any,必须显式类型
# → 每条都能直接执行
# → AI 违反时你能立刻发现5.3 模块分层:全局规则 vs 局部规则
不是所有规则都需要全局生效。聪明的做法是分层管理:
| 层级 | 作用范围 | 示例 | 文件位置 |
|---|---|---|---|
| 全局规则 | 整个项目 | 统一包管理器、命名规范 | CLAUDE.md / .cursorrules |
| 局部规则 | 特定目录 | API 目录的约定、测试目录的约定 | .mdc frontmatter / 子目录规则 |
| 按需挂载 | 命中路径时激活 | 只在编辑src/api/时加载 API 规则 | Glob 路径匹配 |
5.4 CLAUDE.md 模板示例(控制在 1-2K Token)
CLAUDE.md 是 Claude Code 的项目规则文件。控制在 1-2K Token 的原因是:太长会被模型忽略,太短又不够用。
# CLAUDE.md
## 项目概述
一个基于 Next.js 14 + Prisma + PostgreSQL 的电商后台
## 技术栈
- Runtime: Node.js 20 LTS
- Framework: Next.js 14 (App Router)
- ORM: Prisma 5.x
- Database: PostgreSQL 15
- Auth: NextAuth.js v5
- Styling: Tailwind CSS 3.x
## 常用命令
- `pnpm install` 安装依赖
- `pnpm dev` 启动开发服务器
- `pnpm build` 生产构建
- `pnpm test` 运行测试
- `pnpm lint` 代码检查
- `pnpm db:push` 同步数据库 Schema
## 编码规范
- 使用函数式组件 + hooks,禁止 class 组件
- Server Component 优先,只在需要交互时用 Client Component
- API 路由统一放在 app/api/ 下
- 数据库查询必须带超时(3s)和错误处理
- 禁止使用 any,必须显式类型定义
## 禁止事项
- ❌ 禁止直接操作 DOM
- ❌ 禁止在客户端组件中访问数据库
- ❌ 禁止使用 moment.js,用 date-fns
- ❌ 禁止 console.log 提交到生产
## 目录结构
src/
├── app/ # Next.js App Router 页面
├── components/ # React 组件
├── lib/ # 工具函数和配置
├── prisma/ # 数据库 Schema 和迁移
└── types/ # TypeScript 类型定义5.5 AGENTS.md 模板示例
AGENTS.md 侧重于定义Agent 的行为边界——它可以做什么、不可以做什么、执行流程是什么。
# AGENTS.md
## Agent 权限
### ✅ 可以做
- 读取项目中的任何文件
- 创建和修改源码文件
- 运行 pnpm install / dev / test / lint
- 查看 Git 状态和日志
### ❌ 不可以做
- 修改数据库数据(只可修改 Schema)
- 删除文件(需人工确认)
- 执行部署命令
- 修改 .env 文件
- 直接推送代码到远程
## 任务执行流程
1. 先理解需求,复述确认
2. 制定修改计划,列出影响范围
3. 执行修改
4. 运行测试验证
5. 报告结果和潜在风险
## 验收标准
- 所有测试通过
- 无 lint 错误
- 无 TypeScript 类型错误
- 修改范围与计划一致5.6 规则文件的版本管理
规则文件不是"写完就忘"的——它需要像代码一样被管理。
- 纳入 Git 管理:规则文件和代码一起版本控制
- 写清楚的 commit message:变更规则时说明原因("禁止 moment.js:团队统一迁移到 date-fns")
- 每季度检查:规则是否仍然准确?有没有新增的约定?有没有过时的禁令?
WARNING
⚠️ 过时规则比没有规则更危险
如果规则文件写着"使用 React 17",但项目已经升级到 React 18——AI 会按照旧规则生成代码,导致版本不兼容。定期 review 规则文件是必须的。
六、避免"上下文污染"与"记忆混乱"
上下文给多了会污染,给错了会混乱。这是上下文工程中最容易被忽视、但危害最大的问题。
6.1 及时截断(New Session)
业务跳转或排错结束时,果断开新会话。这是最简单也最有效的防污染手段。
为什么?因为历史对话中的错误代码、被否决的方案、已经修复的 Bug 描述——这些信息都会干扰 AI 的权重计算。AI 不会自动"忘记"上一轮你让它放弃的方案,它只是降低了权重。当新任务和旧任务有重叠时,这些残留信息就会冒出来。
DANGER
❌ 血泪教训
在一个会话中连续修了 3 个不同模块的 Bug,到第 4 个 Bug 时,AI 开始把第 1 个 Bug 的修复逻辑套用到第 4 个上——因为上下文里还残留着第 1 个 Bug 的错误栈和修复代码。果断开新会话,比任何技巧都管用。
6.2 精准挂载机制
拒绝盲目扔给大模型整个src树。利用@文件语法,仅挂载直接依赖的文件。
❌ 盲目挂载
# 修一个 Button 组件的样式 Bug
@src (200+ 文件)
# AI 被无关代码干扰
# 可能参考了错误的组件
# Token 浪费严重✅ 精准挂载
# 修一个 Button 组件的样式 Bug
@src/components/ui/Button.tsx
@src/styles/globals.css
@tailwind.config.ts
# AI 聚焦核心文件
# 参考信息准确
# Token 高效利用6.3 不把相互矛盾的要求混在同一轮
每次会话聚焦一个目标。如果需要改变方向,先开新会话,或者显式声明"之前的 XX 要求作废,现在改为 YY"。
重要约束要重复显式声明——不要假设 AI "应该记得"你 20 轮对话前说的规则。在关键节点重新声明核心约束,是防止记忆混乱的有效手段。
6.4 上下文供给检查清单
每次开新任务前,花 30 秒过一遍这个清单:
- ☐ 目标是否清晰?
- ☐ 技术栈是否说明?
- ☐ 修改范围是否明确?
- ☐ 关键约束是否列出?
- ☐ 是否有输入/输出示例?
- ☐ 是否要求模型复述理解?
- ☐ 是否要求列出风险和假设?
- ☐ 上下文是否有过时/矛盾信息?
INFO
💡 "先复述,再执行"工作流
在给 AI 下达复杂任务时,先加一句:"在执行之前,请先复述你对任务的理解,列出你计划修改的文件和潜在风险。"这 30 秒的确认,能避免 30 分钟的返工。
七、团队知识资产沉淀与分发
上下文工程不只是个人技能,更是团队基础设施。一个人的经验如果不能沉淀为团队资产,那每次新人入职都要重新踩一遍坑。
7.1 构建团队公用的 Prompt 模板库
按场景分类,每个模板附带"使用场景"和"常见陷阱"说明:
| 场景 | 模板名称 | 核心内容 |
|---|---|---|
| 功能开发 | feature-dev.md | 需求理解 → 设计 → 编码 → 测试的完整流程 |
| Bug 修复 | bug-fix.md | 复现 → 定位 → 修复 → 验证的标准化步骤 |
| 代码审查 | code-review.md | 安全检查、性能检查、风格检查的清单 |
| 测试生成 | test-gen.md | 单元测试 + 集成测试 + 边界用例的生成策略 |
7.2 复杂构建/部署脚本固化
不要让 AI 每次都重新"发明"部署流程。把复杂的构建和部署脚本固化至 Makefile / npm scripts中,将需要大模型执行的动作最小化为一条命令:
# package.json
{
"scripts": {
"deploy:staging": "make deploy ENV=staging",
"deploy:prod": "make deploy ENV=production",
"db:migrate": "prisma migrate deploy",
"test:e2e": "playwright test --project=chromium"
}
}
# AI 只需要执行:pnpm run deploy:staging
# 而不是让 AI 自己写部署命令7.3 共享失败案例与修复记录
这是最被低估的团队资产。每次踩坑都记录下来:
# 团队知识库:踩坑记录
## 2026-06-15:Prisma 事务超时
- 现象:批量插入 1000 条数据时事务超时
- 原因:Prisma 默认事务超时 5s,批量操作需要更长时间
- 修复:设置 transactionOptions: { maxWait: 10000, timeout: 30000 }
- 教训:批量操作必须显式设置事务超时
## 2026-06-20:Next.js 动态导入 SSR 问题
- 现象:dynamic import 的组件在 SSR 时报 window is not defined
- 原因:未设置 ssr: false
- 修复:next/dynamic({ ssr: false })
- 教训:浏览器专用组件必须禁用 SSR7.4 新成员入职加速
有了规则文件 + 模板库 + 踩坑记录,新成员的入职速度可以提升 3-5 倍:
- 规则文件(CLAUDE.md / .cursorrules):让 AI 自动遵守项目约定
- 模板库:让新人直接用成熟的 Prompt 模板,不用从零摸索
- 模块上下文文档:每个核心模块的"地图",新人不用读全部代码
- 踩坑记录:避免新人重复踩已知的坑
INFO
✅ 团队上下文资产清单
一个成熟的 AI 编程团队应该拥有:① 项目规则文件(CLAUDE.md / .cursorrules)② 场景化 Prompt 模板库 ③ 模块上下文文档 ④ 踩坑记录与修复方案 ⑤ 固化的构建/部署脚本。这 5 项资产,就是团队的"上下文基础设施"。
八、总结:Prompt 决定你问什么,Context 决定模型知不知道
这章的核心结论其实很简单:
Prompt 解决“提问方式”,Context 解决“事实供给”。
你可以把 Prompt 写得很漂亮,但如果上下文是旧的、乱的、缺的、冲突的,模型照样会一本正经地胡说。反过来,你哪怕 Prompt 朴素一点,只要上下文分层清楚、顺序合理、证据充分、规则明确,输出通常都会稳很多。
所以真正的 Context Engineering,不是“把更多 token 塞进去”,而是:
- 先给地图,再给地形
- 先给证据,再给猜测
- 先给稳定前缀,再给动态尾巴
- 先定规则,再开执行
- 先验证,再沉淀成长期知识
评论与讨论
如果这篇文章对你有帮助,或你对实现细节有不同判断,可以直接在这里继续讨论。